
India's first GenAI unicorn paused its foundation model and chip work on May 5, 2026. The harder question is what that means for the thousand-plus Indian SMEs now permanently downstream of OpenAI, Anthropic, and Google.
Krutrim Just Pivoted. Your AI Stack Did Not.
On Tuesday, May 5, Krutrim's spokesperson confirmed what most of the AI ecosystem already suspected — chip design paused, foundation model work paused, the consumer Kruti app already dead since April 16. The company is "concentrating resources on building and scaling its core AI cloud services stack." India's first GenAI unicorn has stopped trying to build models and started trying to rent GPUs (Medianama, May 2026).
The Krutrim story is interesting. It is not, however, the story that matters for you.
The story that matters is the one playing out at a desk in Pune or Koramangala or Lower Parel right now. The founders we're working with this quarter are running customer support on GPT-4o, GST OCR for vendor invoices on Gemini 2.5 Pro, lead scoring on Claude Sonnet. They read the Krutrim news between two Slack messages, felt vaguely patriotic disappointment, and went back to work. They have not yet noticed that their entire AI architecture is now permanently downstream of three foreign companies, billed in USD, with no Indian foundation-model alternative inside their latency and accuracy tolerance for at least three years.
That is the architecture this post is about.
The Stack You Are Actually Running
Pull up your last OpenAI invoice. There is a number in dollars. There is no GSTIN on it (CA Ajay Gupta documented this on Anthropic invoices in early 2026 — open OIDAR compliance question). There is a 2–3% forex skim that your card issuer takes on the conversion. And under the IGST Amendment Act 2023, effective October 1, 2023, that invoice triggers an 18% Reverse Charge Mechanism liability — you self-invoice within 30 days under Rule 47A, pay IGST in cash from the electronic cash ledger (you cannot use ITC to pay RCM liability), and reclaim ITC if you are GST-registered.
If you are below the ₹40L–₹75L threshold and not registered, that 18% is not a cash flow hit. It is a permanent cost.
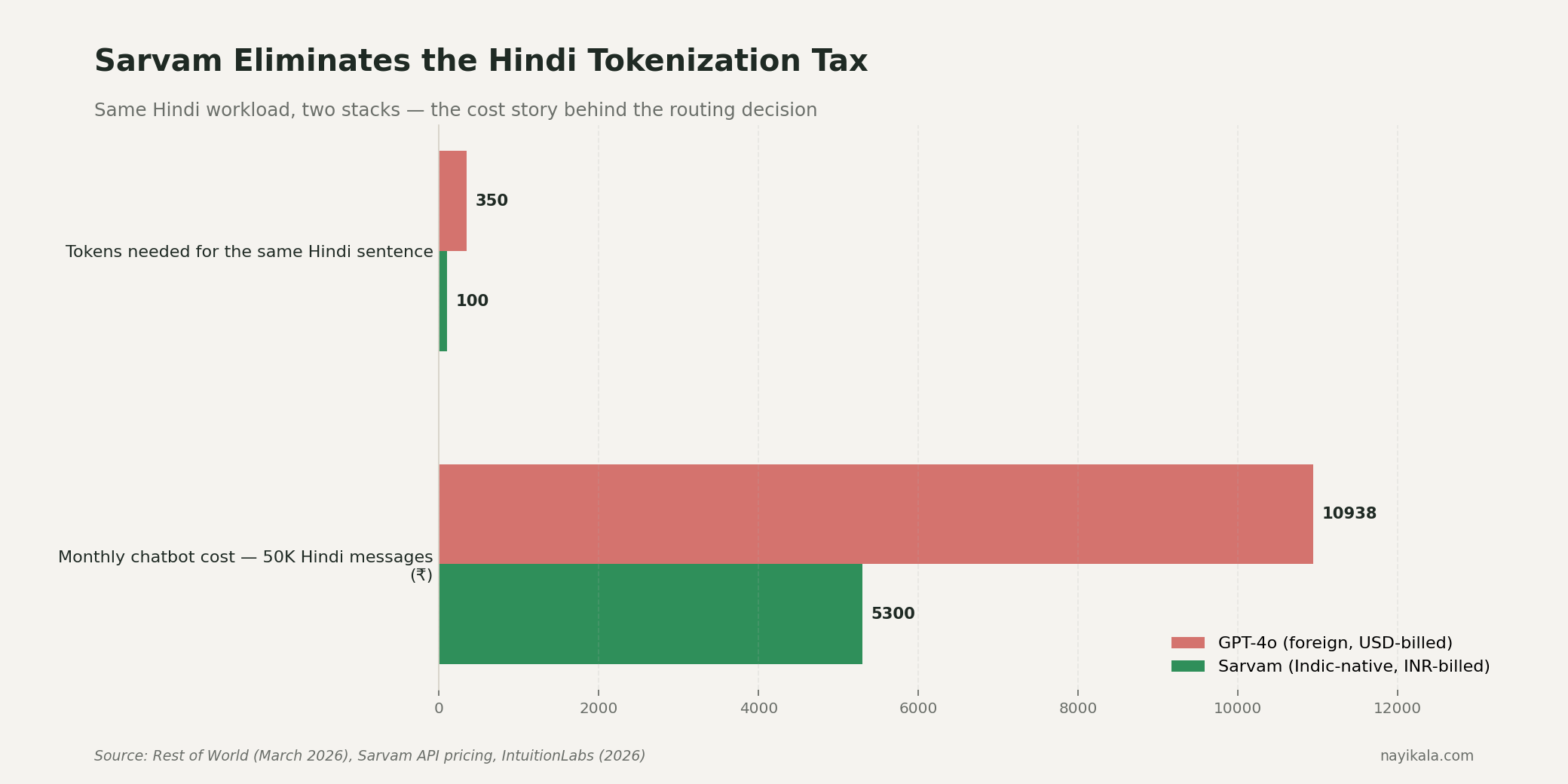
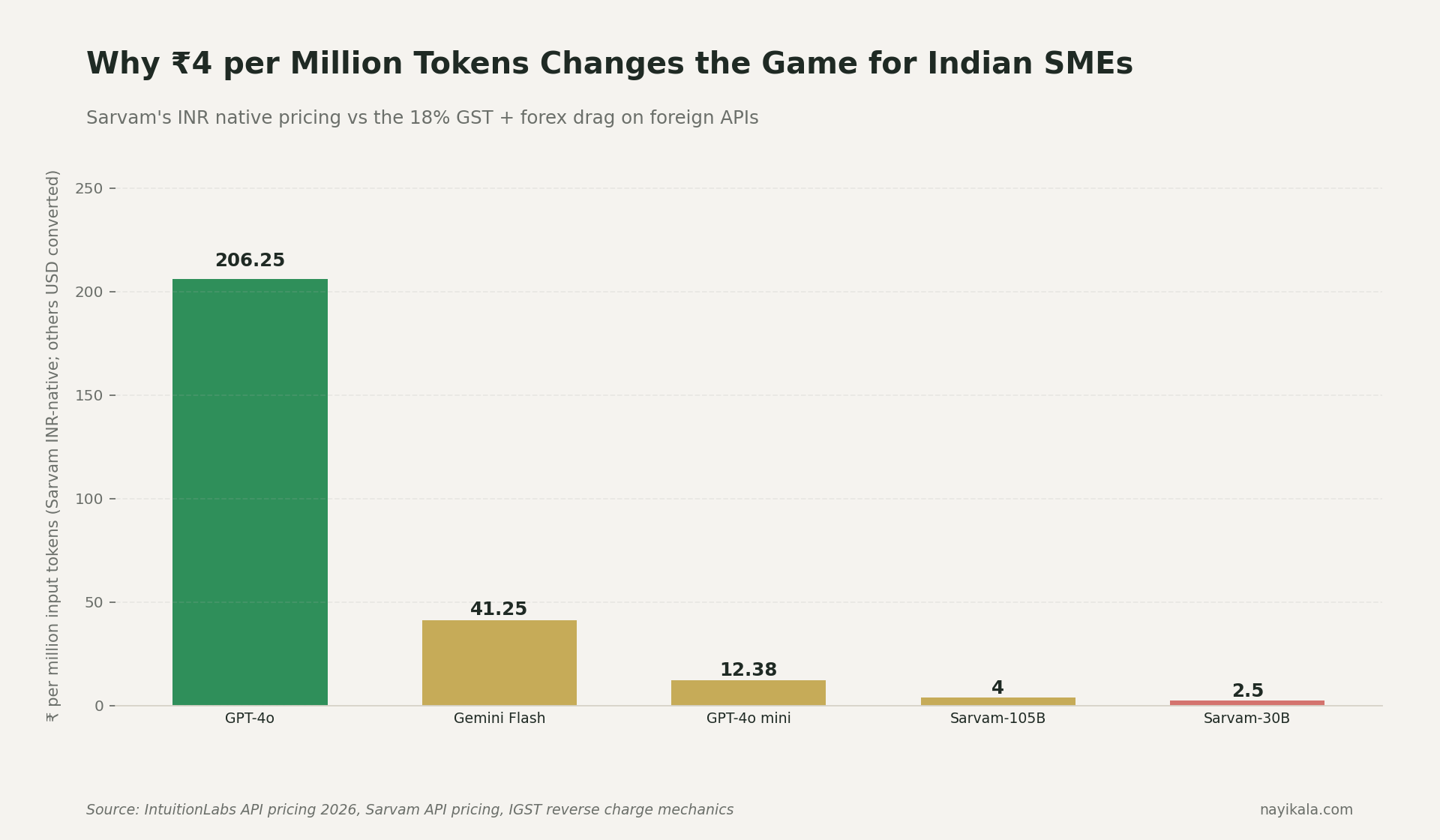
Now layer on the workload. Hindi queries on GPT-4o consume 3–4× the tokens of the same English sentence (Rest of World, March 2026). A ₹100 English query becomes a ₹300–400 Hindi query. The customer doesn't care. They typed in Devanagari. You eat the multiplier.
And the multiplier buys you a Word Error Rate of 33.9% on Hindi voice versus Sarvam Audio V3's 5.0% on the Voice of India benchmark, jointly built by Josh Talks and AI4Bharat at IIT Madras (Feb 2026). On Gujarati it is GPT-4o at 98.2% WER versus Sarvam at 12.8%. GPT-4o mini hits 297% WER on Gujarati — practically unusable. Practical usability threshold is under 20%.
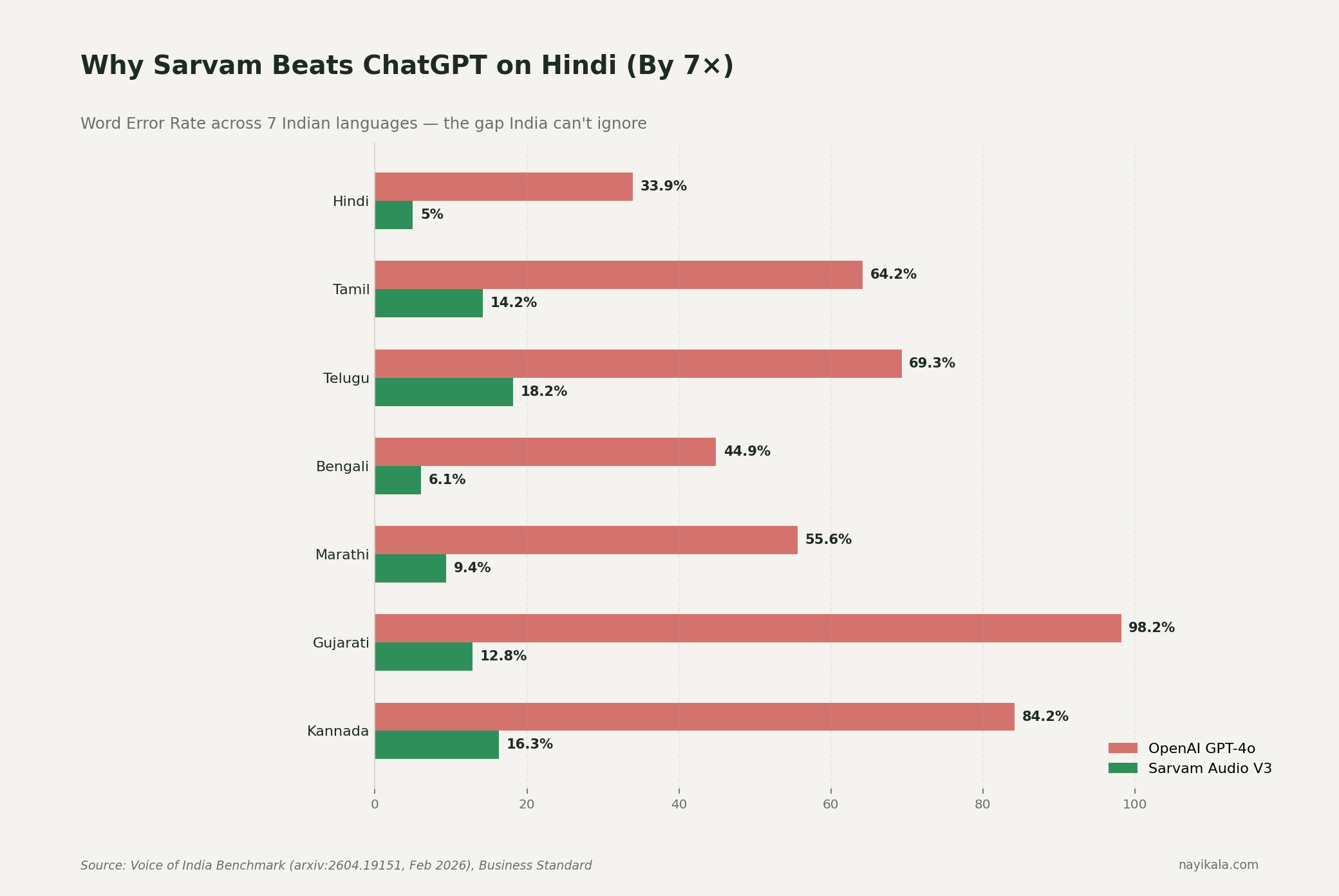
So the architecture you have is: paying 3–4× more, in dollars you don't earn, to get a 7× worse result, on the language half your customers actually speak. (More on the Hindi tokenization penalty and Sarvam accuracy gains here.)
That is the room you are sitting in. Krutrim's pivot didn't put you in it. It just turned the lights on.
Why "An Indian Alternative Is Coming" Is Not A Plan
Here is the part that needs to be said cleanly: India will not have its own foundation-model winner that catches GPT-5. The country missed that window in 2023, and there is no $200M+ Indian VC ready to bankroll an 18-month training run that lands below the open-source frontier.
The economics are public. GPT-4 cost $40M–$78M in compute alone (Epoch AI). Gemini Ultra was around $191M. Llama 3.1 405B was around $170M. Cost growth is 2.4× per year since 2016 (Epoch AI), implying $1B single-training runs by 2027. Dario Amodei said the quiet part out loud in 2024: "Close to a billion dollars would be spent on a single training run."
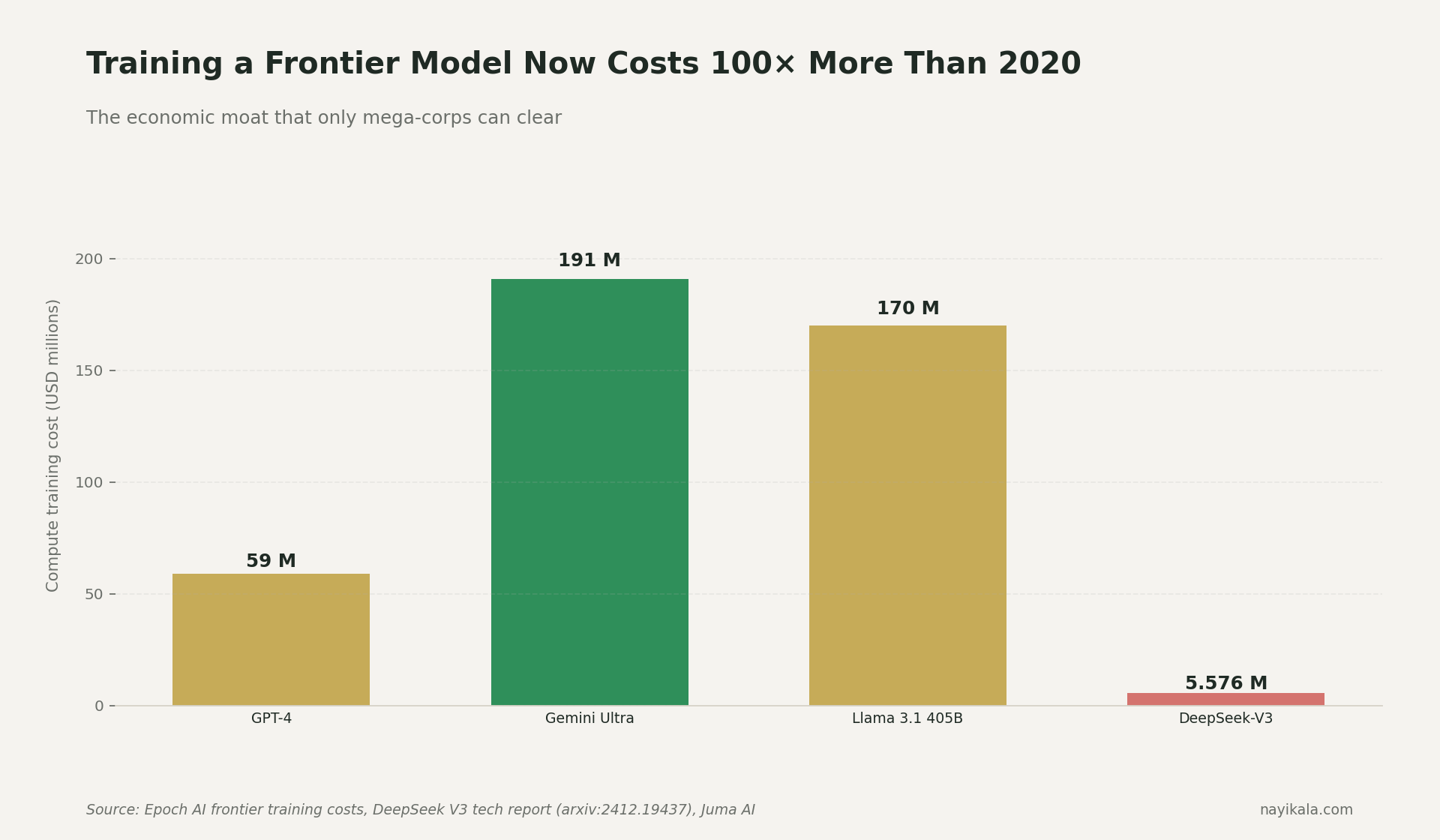
Krutrim raised about $74.9M from outside investors, plus Bhavish Aggarwal's personal $230M family-office commitment and equity-pledged debt. Aleph Alpha — the cleanest precedent — raised $500M out of Heidelberg, hit roughly €20M ARR, and pivoted on September 5, 2024 with CEO Jonas Andrulis saying: "The world changed. Just having a European LLM is not sufficient as a business model." On April 24, 2026, Cohere bought Aleph Alpha. The thing Cohere paid for was PhariaAI — the deployment and governance layer — not the foundation models. Andrulis was ousted before close.

Eighteen months later, the same arc has now played out in India. It is the second time. It will not be the last. Kai-Fu Lee folded 01.AI's pre-training in March 2025 and put it bluntly: "A pre-trained model can only be justified by amassing hundreds of millions of users. Alibaba can justify it, Google can justify it, DeepSeek can justify it. The rest of us can't." Baichuan pivoted to medical AI. Aleph pivoted to deployment. Krutrim has pivoted to cloud.
Sarvam is the single Indian outlier — $350M raised from Nvidia, Bessemer, Amazon, Accel in April 2026; Sarvam-30B and Sarvam-105B released February 18, 2026 under Apache 2.0; selected by MeitY for the national sovereign LLM. It is excellent at Indic. It is not catching GPT-5. That is a fine reality if you architect for it. It is a disaster if you keep waiting for it.
Where Value Actually Accrues — And It Is Not The Model Layer
While Krutrim spent two years training Krutrim-1 and Krutrim-2 on its own infrastructure, Cursor (Anysphere) went from $100M ARR in January 2025 to $2B ARR by February 2026. Thirteen months. Built on top of Claude and GPT. Zero foundation-model investment. Currently in talks at a $50B valuation.
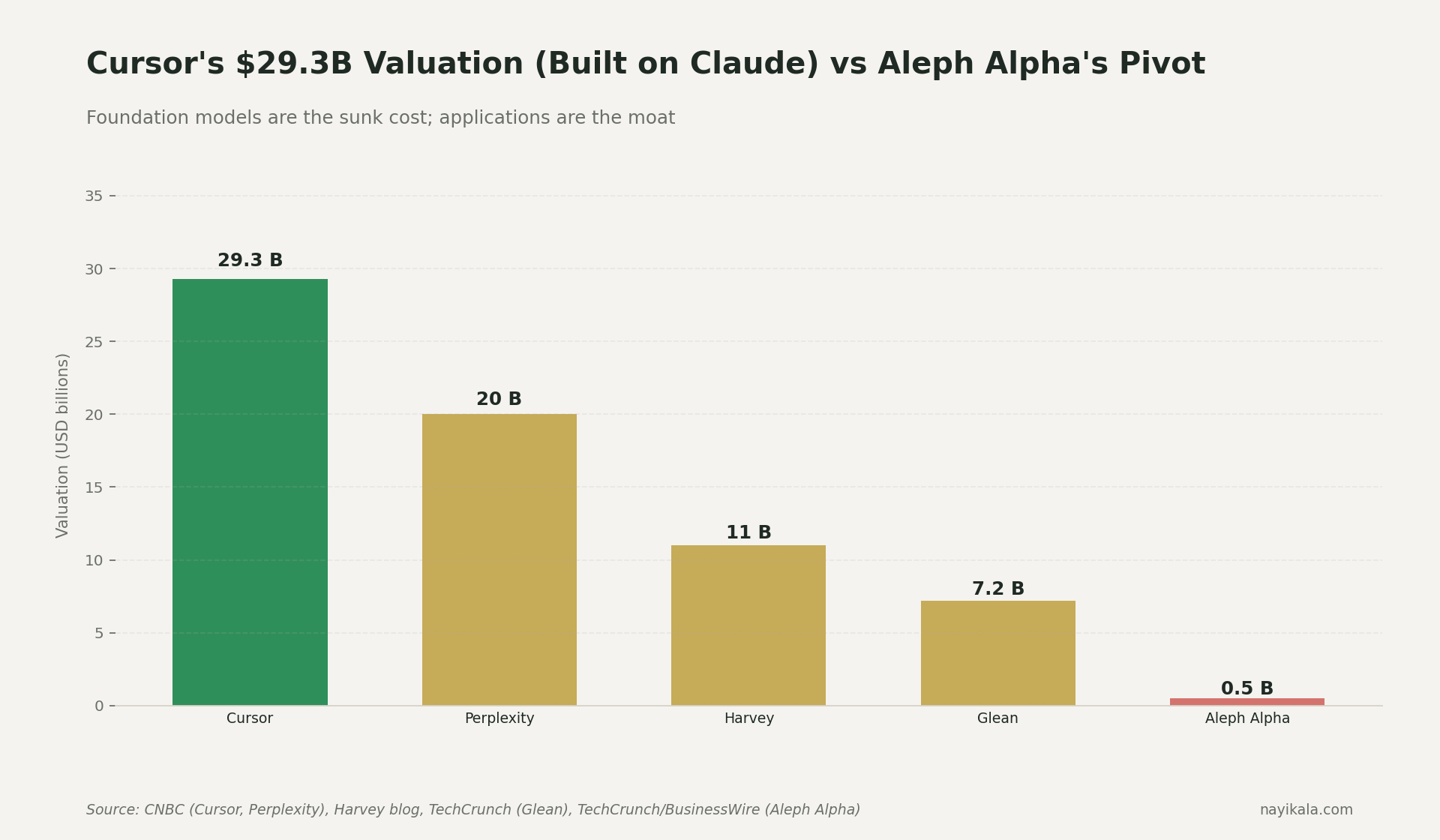
Harvey did $190M ARR on GPT, valued at $11B in March 2026. Perplexity is at roughly $500M annualized at a $20B valuation, 335% YoY growth, 100M+ MAU. Glean is at $7.2B on enterprise search across multiple LLMs.
The pattern is not subtle. Value accrues at the workflow layer. The model is a commodity input that gets cheaper every quarter — GPT-class output pricing has dropped about 79% per year on the DeepLearning.AI metric since 2023. The defensibility lives in: which model runs which query, on which data, under which compliance regime, with which fallback, billed in which currency, logged for which audit.
That is the layer Indian SMEs need. Nobody is building it for them by default.
What You Can Do This Quarter
These are engineering moves, not strategy. Do them in order.
1. Map your tokens by language. Pull your last 30 days of API logs. Tag every request as English-only, Indic-only, or mixed. Multiply Indic token count by 3.5× — that is your actual Hindi tokenization tax. If Indic is more than 20% of your spend, you are losing money on every Indic call to a foreign model.
2. Route Indic workloads to Sarvam. Sarvam-105B is ₹4 input / ₹16 output per million tokens, INR-billed. A 50,000-message/month chatbot at 500 tokens average lands around ₹8,500/month. This is not a patriotic alternative. It is a 7× accuracy gain at lower cost on Indic. The English half of your stack stays on GPT-4o or Claude — they remain the right call there.
3. Build multi-model routing as architecture, not as backup. A request enters your system. Before it hits any model, it gets classified — language, sensitivity, latency budget, customer geography. The router picks Sarvam, GPT-4o, Claude, or an on-prem deployment. Logs go to one place. Spend tracking goes to one place. This is a week of engineering work and it is the single highest-ROI piece of infrastructure you can build right now. We unpacked one variant of this — routing Indic support workloads to the right model — under the AIGEG framing.
4. Get GST-aware on API spend. Anyone with foreign API invoices needs Rule 47A self-invoicing within 30 days, IGST 18% paid in cash, GSTR-3B RCM column populated. If your books don't show this, your CA will find it later, and "later" is more expensive. (How GST ITC and RCM compliance plug into your spend ledger.)
5. Classify data before the API call, not after. PII, payment data, health data, minor data — tagged at ingestion. RBI's April 2018 circular requires payment system data to be repatriated from foreign servers within 24 hours of processing. That binds today, with no DPDP grace period. If you're sending transaction details or beneficiary data to OpenAI without a 24-hour purge, that's a direct violation of an existing RBI circular, not a future risk.
6. Get on the IndiaAI Mission compute list for sensitive workloads. Subsidised rate is ₹65–67/GPU-hour versus international H100 rates of $3–5/hr (~₹250–415). Yotta, Jio, Tata Communications, E2E, CtrlS are all empaneled. For batch processing of regulated data, this changes the math.
The Three Walls Closing In
You have a window. It is not as long as you think.
Wall one — RBI payment data, today. The 24-hour repatriation rule is in force. If you process payments and your AI vendor is foreign, you are already non-compliant unless you have a hard purge mechanism. Show me the cron job. Show me the audit log.
Wall two — RBI FREE-AI, August 2025. Currently advisory, chaired by Prof. Pushpak Bhattacharya. The framework explicitly prefers "indigenous sector-specific AI models" over generic third-party LLMs and asks FIs to validate third-party models as rigorously as internal ones. This is expected to harden into binding master directions in 18–24 months. If your fintech or insurance roadmap goes that far, you need an indigenous-preference posture in your architecture diagrams now.
Wall three — DPDP cross-border, May 13, 2027. Final Rules notified November 13, 2025 (Gazette G.S.R. 846(E)). Phase 3 — Rules 3, 5–16, 22, 23 — activates the substantive obligations including Rule 12 (Significant Data Fiduciary obligations, including potential data localization for specified categories) and Rule 15 (cross-border transfer restrictions). Penalty cap for security failures is ₹250 cr. No company has been fined yet. The DPBI's penalty powers don't activate until that date. After that date, they do. The architectural building blocks for DPDP consent and cross-border data obligations are what you wire in now, not in 2027.

So here is the question worth sitting with: what is your architecture's exit when the model you depend on raises prices, gets hit by an export control, or your customer's payment data ends up flagged under DPDP Rule 12 because you've been classified an SDF? If the answer is "we'll figure it out then," you are doing what Aleph Alpha and Krutrim did, in miniature, on a slower clock.
What Is Actually Buildable
The layer India can actually have — and the layer we build for — is the workflow layer. The router that knows when to send a query to Sarvam and when to send it to Claude. The data classifier that runs before the API call. The GST-aware spend ledger. The 24-hour payment data purge. The audit trail that satisfies RBI today and DPDP in May 2027.
The model layer is settled. The compliance and routing layer is wide open.
The integration map between Indic models, foreign models, IndiaAI Mission compute, and on-prem fallback is where the real design decisions live.
Related reading
← All posts


