
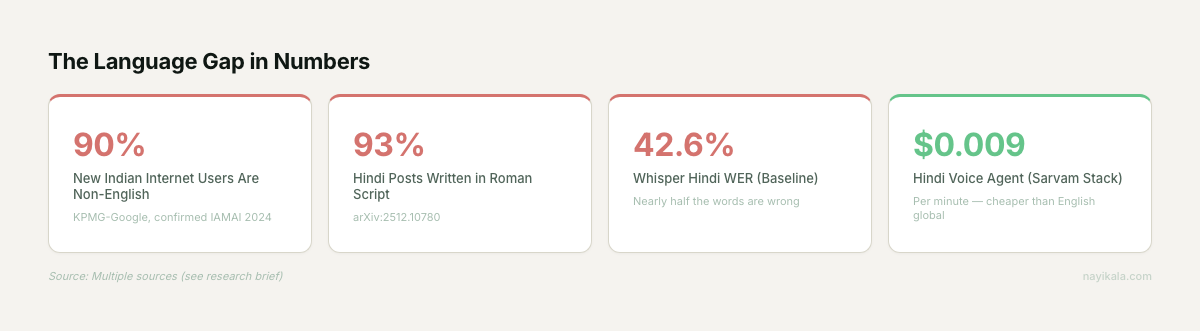
90% of India’s new internet users don’t speak English. Most business automation stacks are English-only. The gap between those two facts is where leads go to die.
Your customer in Indore types "mujhe price batao" into your WhatsApp chatbot. The bot responds in English. The customer sends a voice note in Hindi. The bot doesn’t understand. The customer leaves. Your CRM logs it as "session ended" — no lead, no sale, no trace of what went wrong.
This happens thousands of times a day across Indian businesses that have invested in automation but built it in the wrong language. The tools work. The intent is there. The customer showed up ready to buy. But somewhere between the Roman-script Hindi message and the English-only NLP pipeline, the conversation died.
The thing is, the customer was never going to switch to English. 90% of new internet users in India are non-English speakers (KPMG-Google, directionally confirmed by IAMAI 2024). The Hindi belt — Uttar Pradesh, Madhya Pradesh, Rajasthan, Bihar — has the lowest MSME Digital Maturity Index score at 55.8. The largest population of potential customers, the lowest digital adoption. That’s not a coincidence. It’s a language problem dressed up as a technology problem.
The English-Only Stack Is Quietly Expensive
Every business we’ve onboarded that had "automated" customer communication was running an English-first stack — sometimes without realizing it. The chatbot provider defaults to English. The CRM templates are in English. The IVR menu might offer Hindi, but the actual AI processing happens in English with a translation layer bolted on top.

Here’s what that costs you in practice.
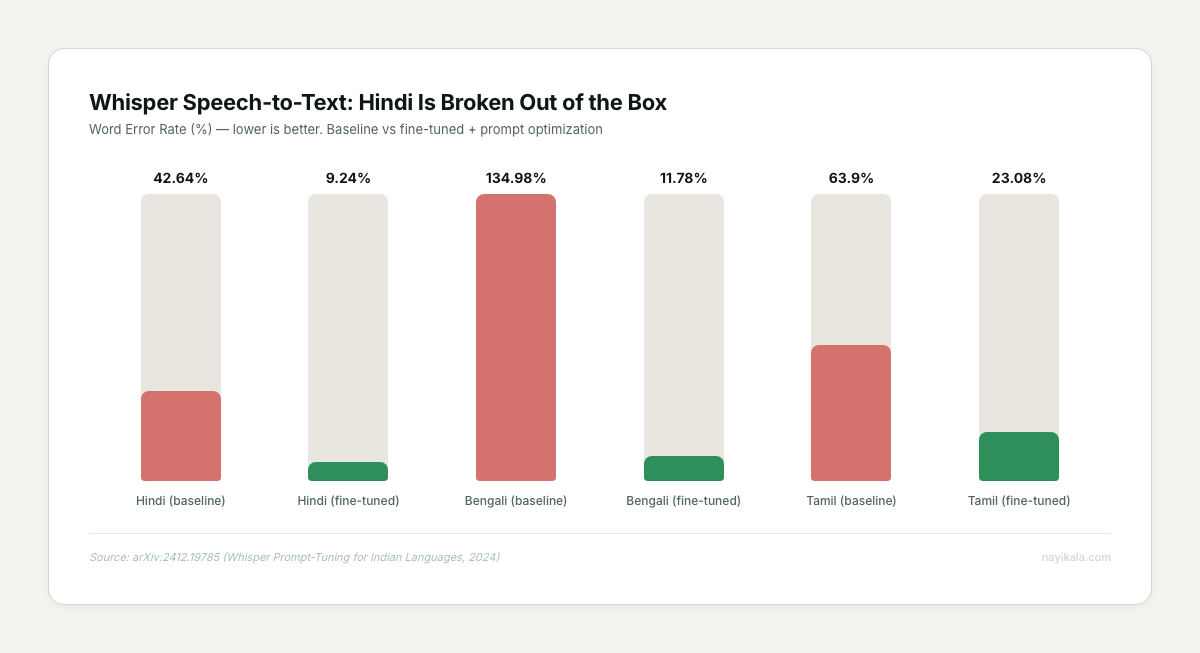
Speech-to-text accuracy collapses. OpenAI’s Whisper — the most commonly used open-source transcription model — has a baseline Word Error Rate of 42.64% on Hindi (arXiv:2412.19785). That means nearly half the words are wrong. For Bengali, it’s worse: 134.98% WER, meaning the model hallucinates more words than the speaker actually said. For comparison, English WER on the same model sits under 10%.
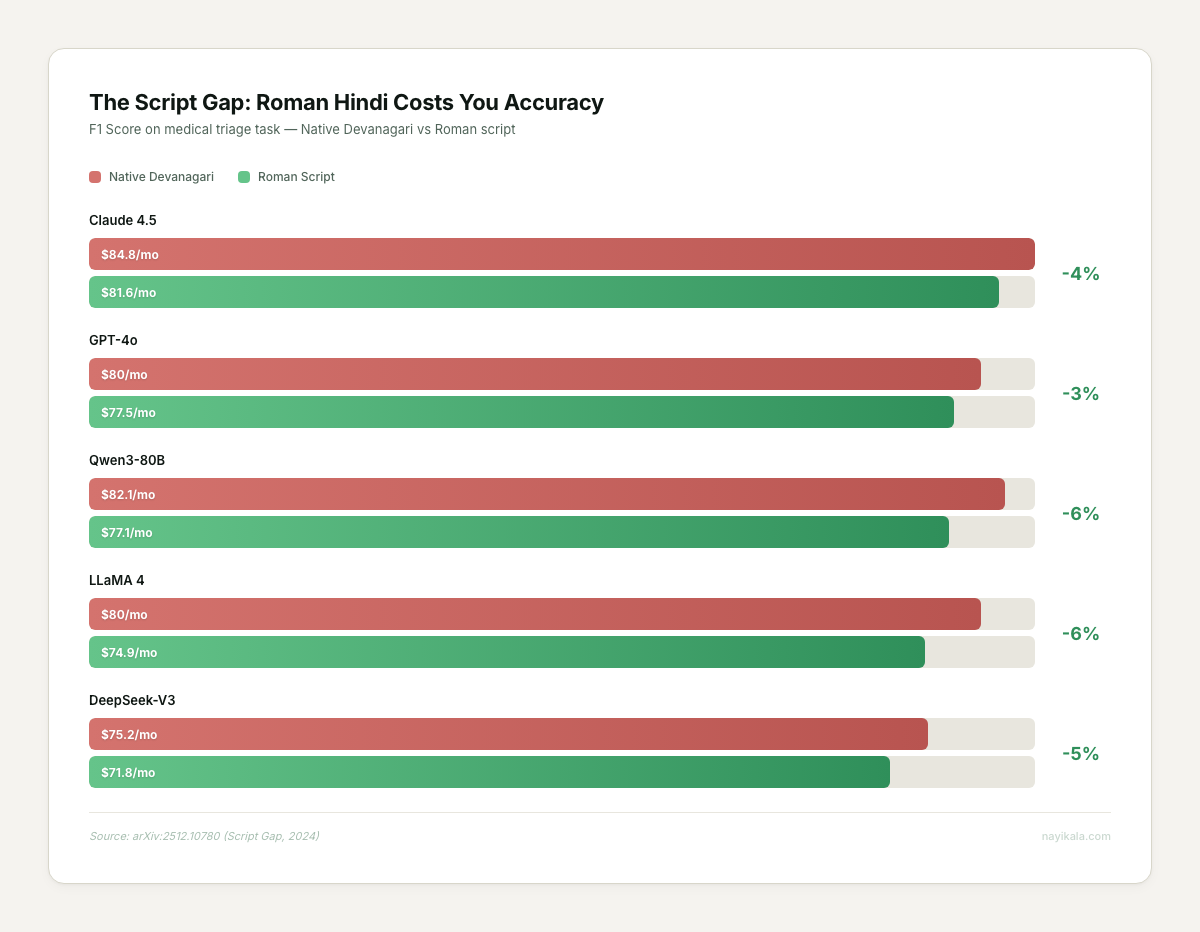
Your customers type in Roman script, but your models expect Devanagari. 93.17% of native Hindi speakers write on social media in Roman script — "kya price hai" instead of "क्या प्राइस है" (arXiv:2512.10780). Roman-script Hindi produces significantly higher token-level entropy — 5.6 bits versus 3.6 for Devanagari. The LLM is working harder and getting worse results. Without a transliteration layer that converts Roman Hindi to Devanagari before inference, you’re looking at a 9.9-point F1 score drop in classification tasks.
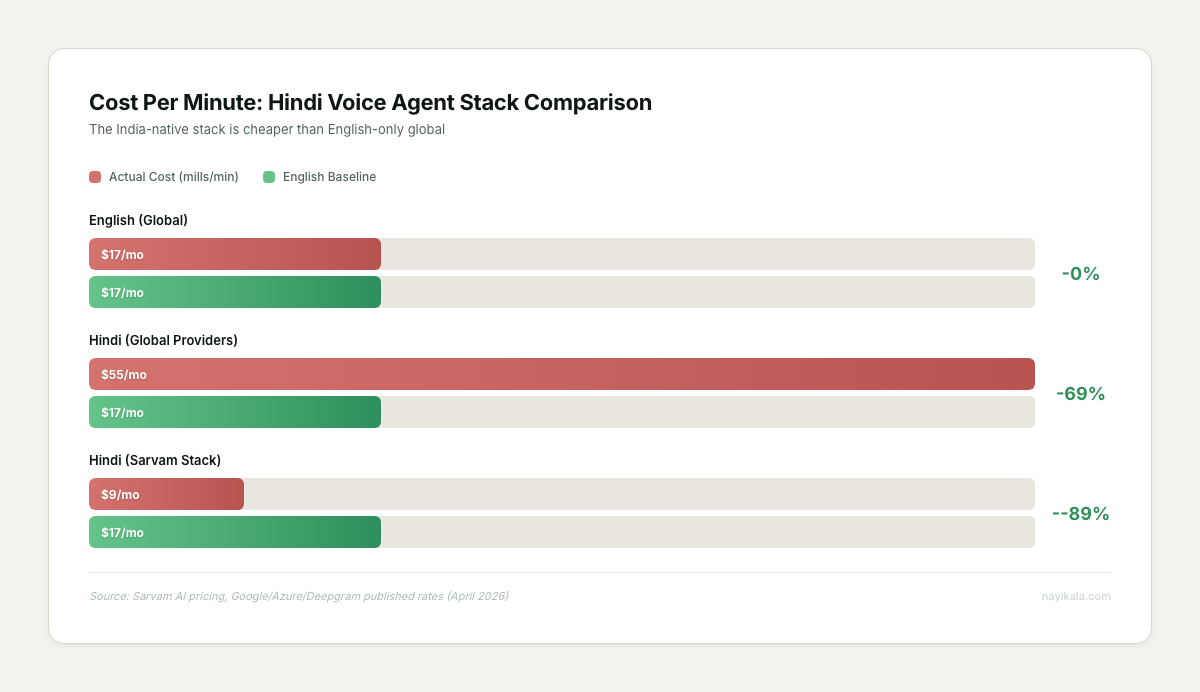
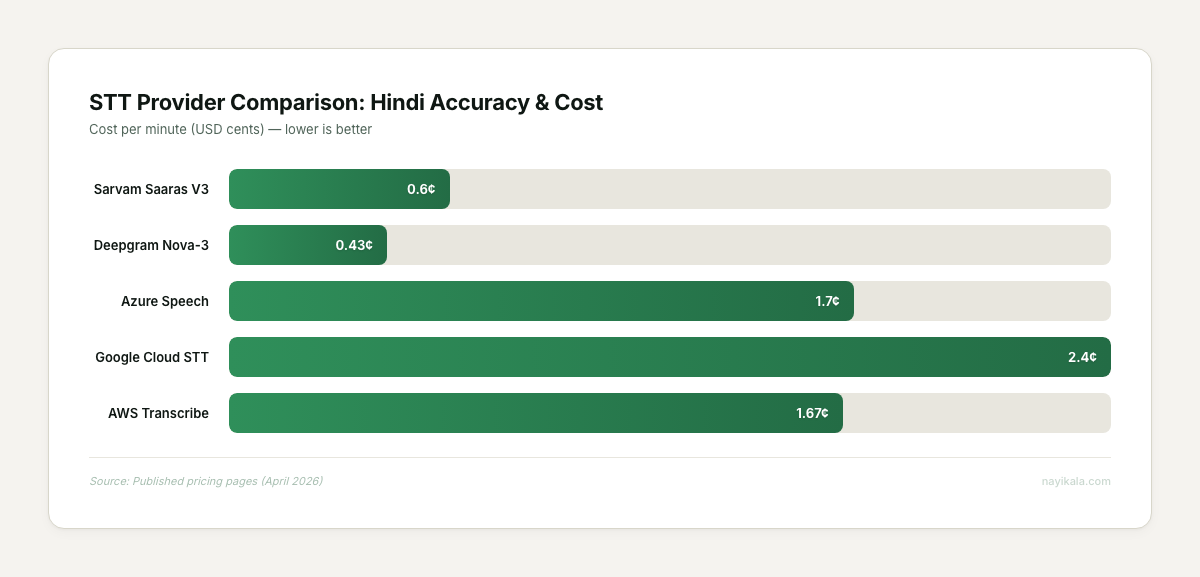
The cost math is upside down. Running a Hindi voice agent on global providers (Google STT + GPT-4o + Azure TTS) costs roughly $0.055 per minute — 3x the cost of an equivalent English stack at $0.017/min. The teams we’ve talked to see this and conclude Hindi automation is too expensive. They’re looking at the wrong price list.
The businesses we’ve seen abandon chatbots within six months almost always built on an English-first architecture and tried to patch in Hindi afterward. Industry-wide, the attrition is staggering — 90% of AI chatbots deployed in 2025 failed to sustain engagement (LoopReply). The architecture was wrong from day one.
What You Can Do Monday Morning
You don’t need a new vendor or a budget approval to start fixing this.
Audit your language gap
For one week, export every WhatsApp conversation your business had. Categorize each message: English, Hindi (Devanagari), Hindi (Roman script), Hinglish, or other regional language. When we’ve run this audit during onboarding, the Roman Hindi percentage lands above 70% every time, and the bot’s comprehension rate on those messages sits below 40%.
Test your chatbot in the customer’s language
Send your own chatbot ten messages in Roman-script Hindi. Common ones: "price batao", "delivery kab hogi", "kal ka order cancel karna hai", "koi discount milega kya". Screenshot the responses. If even three of those ten get a useful reply, you’re ahead of most.
Switch your WhatsApp Business greeting to Hindi-first
WhatsApp supports 11 Indian languages natively. Change your auto-greeting from English to Hindi (or your dominant customer language). Max Life Insurance saw 40% of users complete journeys in their native language after adding vernacular support, with an 80% completion rate among vernacular customers (Haptik case study). Your greeting is the first signal that your business speaks their language.

Use Bhashini for free translation
The government’s Bhashini platform handles 100 million+ monthly inference calls across 35+ languages. It’s free API access. It won’t replace a production system, but it’s good enough to prototype a translation layer for your most common customer queries. Build a simple lookup: top 50 customer questions in Hindi, mapped to your standard responses.
Track voice notes separately
If your customers send voice notes on WhatsApp — and in Tier 2/3 cities, they overwhelmingly do — start logging how many you receive versus how many get a useful response. Every business we’ve audited has zero automation on voice notes. That’s the baseline you need to measure against.

Where It Gets Harder
The Monday-morning fixes give you visibility into the problem. The structural fix is a different kind of work.

A Hindi-first AI stack isn’t a chatbot with a translation plugin. It’s a pipeline with at least four distinct components, each with its own failure modes.
Script detection and transliteration. Before any message hits your LLM, you need to detect whether it’s Roman-script Hindi, Devanagari, Hinglish code-mixed, or something else. Then normalize it. The word "मैं" appears as "main", "mein", "mien", "men", and "me" in Roman script — all in common use, no standard spelling. A naive transliteration layer gets this wrong constantly. Pre-normalization from Roman to Devanagari before LLM inference recovers about 5 F1 points (75.3% to 80.1% on GPT-4o), but the normalization model itself needs to handle the entropy.
STT model selection for telephony. Fine-tuned Whisper on Hindi gets WER down to 9.24%, but that’s on clean audio. Telephony audio is 8KHz, compressed, with background noise. Sarvam’s Saaras V3 is optimized for exactly this — sub-150ms time-to-first-token, Rs 0.50/min, and it handles mid-sentence Hindi-English code-switching. The Indian-native stack (Sarvam STT + Sarvam LLM + Bulbul TTS) comes in at roughly $0.009 per minute — cheaper than an English-only global stack. But stitching those components together with proper failover, latency management, and conversation state is where the engineering lives.
The RAG layer needs to be script-aware. Your knowledge base is probably in English. Your customer asks in Roman Hindi. Standard embedding models (even multilingual ones like mE5) lose retrieval precision across that script boundary. Hindi-specific retrieval models like DeepRAG show a 23% improvement in retrieval precision over general multilingual embeddings (arXiv:2503.08213). The canonical knowledge base needs to live in Devanagari, with incoming queries normalized before lookup. That’s a data architecture decision, not a plugin toggle.
End-to-end latency budget. A viable Hindi voice agent needs to respond in under 1.5 seconds to feel natural. The current achievable stack — Sarvam Saaras V3 (<150ms) + GPT-4o (800-1,200ms) + Bulbul V3 (<400ms) — lands at roughly 1.3-1.8 seconds on first turn. That’s tight. Every additional processing step — transliteration, RAG lookup, consent check — eats into that budget. The latency architecture determines which features you can actually ship.
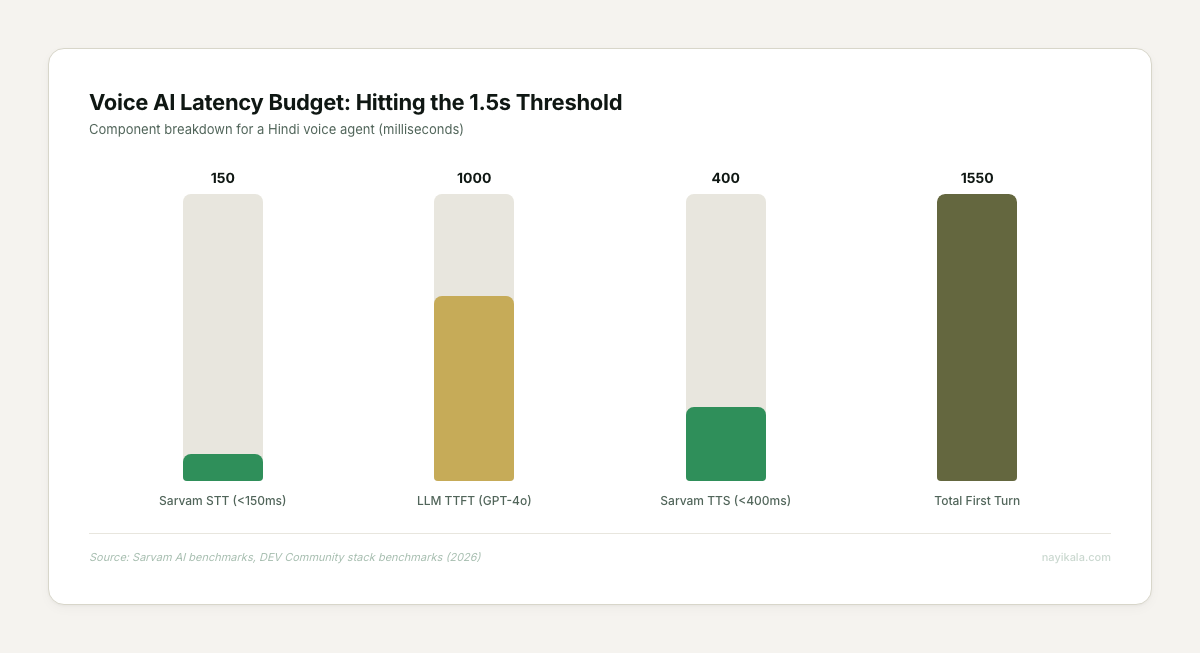
The transliteration pipeline, the script-aware RAG layer, and the telephony-grade latency budget are where the real design decisions live.
← All posts


